Lite³: A Serialized, Schemaless, Zero-Copy Datastore
Showcase video

Get notified when Lite³ releases!
Introduction
Lite³ is a key-value datastructure supporting get(), set() & delete() operations while being always-serialized.
Its unique ability is that it allows mutations directly on the serialized form, not limited to in-place updates. Essentially, it functions as a hybrid between a serialization format and a mutable datastore.
For example:
1. A Lite³ datastructure is received from a socket
2. Without doing any parsing, the user can immediately:
- Lookup keys and read values via zero-copy pointers
- Insert/update/delete arbitrary keys
3. After all operations are done, the structure can be transmitted 'as-is' (no serialization required, just memcpy())
4. The receiver then has access to all the same operations
For human readability, the structure can also be converted to/from JSON, though arrays and nested objects are not yet supported.
Features
- Schemaless & self-describing
- No (de)serialization step required
- Zero-copy reads + writes of any data size
- Convertable to/from JSON for human readability
- Protocol agnostic
- O(log n) amortized time for all operations
- Built-in pointer validation
- Worst-case latency guarantees for real-time applications
- Low memory profile
- No `malloc()`, caller provides buffer
- A single C11 library with ~1000 LOC
- MIT license
Feature matrix
| Format name | Schemaless | Zero-copy reads1 | Zero-copy writes2 | Human-readable3 |
|---|---|---|---|---|
| Lite3 | ✅ | ✅ O(log n) | ✅ O(log n) | ⚠ (convertable to JSON) |
| JSON | ✅ | ❌ | ❌ | ✅ |
| BSON | ✅ | ❌ | ❌ | ⚠ (convertable to JSON) |
| MessagePack | ✅ | ❌ | ❌ | ⚠ (convertable to JSON) |
| CBOR | ✅ | ❌ | ❌ | ⚠ (convertable to JSON) |
| Smile | ✅ | ❌ | ❌ | ⚠ (convertable to JSON) |
| Ion (Amazon) | ✅ | ❌ | ❌ | ⚠ (convertable to JSON) |
| Protobuf (Google) | ❌ | ❌ | ❌ | ❌4 |
| Flatbuffers (Google) | ❌ | ✅ O(1) | ❌ (immutable) | ❌ |
| Flexbuffers (Google) | ✅ | ✅ O(1) | ❌ (immutable) | ⚠ (convertable to JSON) |
| Cap'n Proto (Cloudflare) | ❌ | ✅ O(1) | ⚠ (in-place only) | ❌ |
| Thrift (Apache/Facebook) | ❌ | ❌ | ❌ | ❌ |
| Avro (Apache) | ❌ | ❌ | ❌ | ❌ |
| Bond (Microsoft, discontinued) | ❌ | ⚠ (limited) | ❌ | ❌ |
| ASN.1 | ❌ | ⚠ (limited) | ❌ | ❌ |
| SBE | ❌ | ✅ O(1) | ⚠ (in-place only) | ❌ |
1Zero-copy reads: The ability to perform arbitrary lookups inside the structure without deserializing or parsing it first.
2Zero-copy writes: The ability to perform arbitrary mutations inside the structure without deserializing or parsing it first.
3To be considered human-readable, all necessary information must be provided in-band (no outside schema).
4Protobuf can optionally send messages in 'ProtoJSON' format for debugging, but in production systems they are still sent as binary and not inspectable without schema.
Lite³ explained
JSON comparison
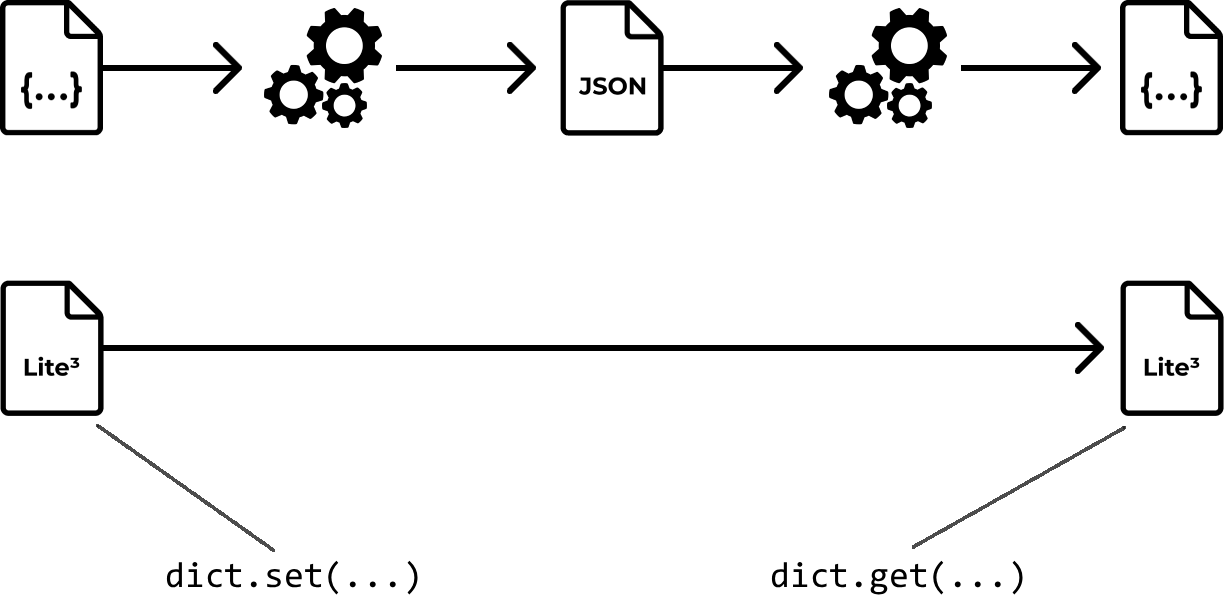
To understand Lite³, let us first look at JSON.
When receiving a JSON-message, it is parsed using JSON.parse() and converted into a 'dictionary object'.
In most cases, the programming language implements a dictionary as a hashmap which supports O(1) constant time lookups, inserts and deletions. In this way, the dictionary acts as the 'intermediate datastructure' to support mutations and lookups.
To send data, the dictionary object must be serialized again using JSON.stringify() back into a JSON string.
In Lite³, lookups, inserts and deletions (get(), set() & delete()) can be directly performed on the serialized form. Since it is already serialialized, it can be sent over the wire at any time.
Think of it as the 'dictionary itself' being sent, thus encoding to a separate string representation becomes unnecessary.
This works because Lite³ structures are always contiguous in memory, unlike most dictionaries which are implemented as hashmaps.
Why B-tree?
Lite³ internally uses a B-tree datastructure.
B-trees are well-known performant datastructures, as evidenced by the many popular databases using them (MySQL, PostgreSQL, MongoDB & DynamoDB).
The reason for their popularity is that they allow for dynamic insertions/deletions while keeping the datastructure balanced and always guaranteeing log(n) operations. Additionally, the nodes sizes can be tuned to disk page sizes, making maximum use of hardware.
However, B-trees are rarely found in a memory or serialization context. For memory-only datastructures, common wisdom rather opts for hashmaps or regular binary trees. B-trees are seen as too 'heavyweight'.
But we can do the same in memory, except that node sizes will be tuned to cache lines, rather than disk pages.
Literature suggests that modern machines have nearly identical latency for 64-byte and 256-byte memory accesses. Currently, Lite³ uses a (configurable) node size of 3 cache lines. Essentially, we create a stripped down micro B-tree specifically adapted for fast memory lookups.
Remember that it is also possible to use Lite³ purely as a memory datastore.
An algorithmic observer will note that B-trees have logarithmic complexity, versus hashmaps' constant time lookups. But typical serialized messages are often small (70% of JSON messages are < 10kB) and only read once. So the difference in logarithmic time vs constant time operations will rarely be noticable except with very frequent updates on large structures (larger than LLC).
More importantly, the Lite³ structure completely eliminates an O(n) parsing and serialization step.
Byte layout
In Lite³, all tree nodes and key-value pairs are serialized inside a single byte buffer.
Tree hierarchies are established using pointers; all parent nodes have pointers to their child nodes:
|----------------|-------|----------------|----------------|-------------|----------------|------------- | ROOT |#DATA##| CHILD #1 | CHILD #2 |#####DATA####| CHILD #3 |####DATA####... |----------------|-------|----------------|----------------|-------------|----------------|------------- | | |___________________| | | | |______________________________________| | |_______________________________________________________________________|
Nodes consist of key hashes stored alongside indexes to key-value pairs (data entries), as well as child node pointers:
NODE
|--------------------------------------------------------------------------------------------|
| h(key1) h(key2) h(keyN) *kv1 *kv2 *keyN *child1 *child2 *child3 *childN |
|--------------------------------------------------------------------------------------------|
| | |
hashed keys kv-pair pointers child node pointers
used for key comparison pointing to data used for tree traversal
entries
The key-value pairs contain the actual data and are stored in between nodes:
KEY-VALUE PAIR KEY-VALUE PAIR KEY-VALUE PAIR |---------|-----------------|----------|-----------------|----------|-----------------| | key 1 | value 1 | key 2 | value 2 | key N | value N | |---------|-----------------|----------|-----------------|----------|-----------------|
- On insertion: The new nodes or key-value pairs are appended at the end of the buffer.
- On deletion: The key-value pairs are deleted in place.
TODO: freed blocks are added to the GC (garbage collection) index.
Over time, freed blocks cause the contiguous byte buffer to accumulate 'holes'. For a serialization format, this is undesirable as data should be compact to occupy less bandwidth. Lite³ will use a defragmentation system to lazily insert new values into the gaps whenever possible. This way, fragmentation is kept under control without excessive data copying or tree rebuilding (STILL WIP, NOT YET IMPLEMENTED).
While it may seem wasteful to store so much metadata inside a serialized message, remember that all of this reduces the operation required to parse/serialize to a single memcpy(). In effect, a tradeoff is made in favour of CPU-cycles under the assumption of ample bandwidth availability.
Despite being a binary format, Lite³ is schemaless and can be converted to/from JSON for human-readability.
Worldwide impact
As of writing, JSON remains the global standard today for data serialization. Reasons include: ease of use, human readability and interopability.
Though it comes with one primary drawback: performance. When deploying services at scale using JSON, parsing/serialization can become a serious bottleneck.
The need for performance is ever-present in today's world of large-scale digital infrastructure. For parties involved, cloud and electricity costs are significant factors which cannot be ignored. Based on a report by the IEA, data centres in 2024 used 415 terawatt hours (TWh) or about 1.5% of global electricity consumption. This is expected to double and reach 945 TWh by 2030.
Building systems that scale to millions of users requires being mindful of cloud costs. According to a paper from 2021, protobuf operations constitute 9.6% of fleet-wide CPU cycles in Google’s infrastructure.
Microservices at Meta (Facebook) also spend between 4-13% of CPU cycles on (de)serialization alone.
Similar case studies of Atlassian and LinkedIn show the need to step away from JSON for performance reasons.
JSON is truly widespread and ubiquitous. If we estimate that inefficient communication formats account for 1-2% of datacenter infrastructure, this amounts to several TWh annualy; comparable to the energy consumption of a small country like Latvia (7.17 TWh in 2023) or Albania (8.09 TWh in 2023). True figures are hard to obtain, but for a comprehensive picture, all devices outside datacenters must also be considered. Despite recent optimizations in JSON-parsing through the use of CPU architectures, the problem remains significant.
Not just big tech, but also hardware devices, IoT and a myriad of other applications across different sectors have spawned a variety of 'application specific' binary formats to answer the performance question.
But many binary formats are domain specific. Or they require rigid schema definitions, typically written using some DSL and required by both sender and receiver. Both must be in sync at all times to avoid communication errors.
Then if the schema should be changed (so-called 'schema evolution'), it is often a complex and laborious task, especially concerning backwards compatibility.
This, combined with lacking integration in web browsers means many developers avoid binary formats despite performance benefits.
Mention of alternative approaches
By making a number of assumptions about the structure of a serialized message, it is possible to (greatly) accelerate the process of encoding/decoding to/from the serialized form.
These techniques come in 3 primary forms:
1. static code generation
This is the approach taken by Protocol Buffers.
Schema desciption .proto files are compiled using the external protoc Protobuf compiler into source code (C++, Go, Java), then for each message type there is corresponding code to encode/decode.
This is also the approach taken by Rust's "serde" crate, although the compilation is performed by the Rust compiler, not an external tool.
The main downside of this approach is that it requires compile-time known schemas.
2. compile-time reflection
'reflection' (a.k.a. introspection) is the ability of a program to inspect and sometimes modify its own structure or behavior.
This approach is used by C++ libraries such as Glaze and cpp-reflect. Notably, C++ is getting reflection in C++26.
Here also the program requires (schema) metadata at compile time, otherwise decoding will fail.
3. runtime reflection
In C#, the JsonSerializer collects metadata at run time by using reflection. Whenever the JsonSerializer has to serialize or deserialize a type for the first time, it collects and caches this metadata.
This approach resembles a JIT-like way to accelerate 'learned' message schema. But the downside is that:
> The metadata collection process takes time and uses memory.
Other environments such as the V8 JavaScript engine employ a 'fast path' for JSON serialization if the message conforms to specific rules. Otherwise, the traditional 'slow path' must be taken.
All of these approaches have upsides and downsides. Ultimately, it is a trade-off between flexibility and performance, combined with the constraints of the programming language and environment.
Purely schemaless formats are simply easier to work with. This fact is evidenced by the popularity of JSON.
For systems talking to eachother, fragmented communications and lack of standards become problematic, especially when conversion steps are required between different formats. In many cases, systems still fall back to JSON for interopability.
Despite being schemaless, Lite³ directly competes with the performance of binary formats.
Get notified when Lite³ releases!